
Feature Pyramid Networks for Object Detection
目的
识别不同尺寸的物体是目标检测中的一个基本挑战,而特征金字塔一直是多尺度目标检测中的一个基本的组成部分,但是由于特征金字塔计算量大,会拖慢整个检测速度,所以大多数方法为了检测速度而尽可能的去避免使用特征金字塔,而是只使用高层的特征来进行预测。高层的特征虽然包含了丰富的语义信息,但是由于低分辨率,很难准确地保存物体的位置信息。与之相反,低层的特征虽然语义信息较少,但是由于分辨率高,就可以准确地包含物体位置信息。所以如果可以将低层的特征和高层的特征融合起来,就能得到一个识别和定位都准确的目标检测系统。所以本文就旨在设计出这样的一个结构来使得检测准确且快速。
FPN结构
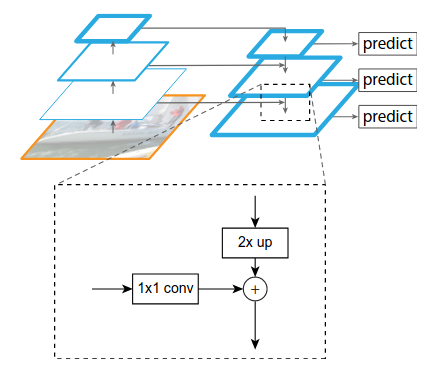
为了使得不同尺度的特征都包含丰富的语义信息,同时又不使得计算成本过高,作者就采用top down和lateral connection的方式,让低层高分辨率低语义的特征和高层低分辨率高语义的特征融合在一起,使得最终得到的不同尺度的特征图都有丰富的语义信息。
bottom-up
Bottom-up的过程就是将图片输入到backbone ConvNet中提取特征的过程中。Backbone输出的feature map的尺寸有的是不变的,有的是成2倍的减小的。对于那些输出的尺寸不变的层,把他们归为一个stage,那么每个stage的最后一层输出的特征就被抽取出来。以ResNet为例,将卷积块conv2, conv3, conv4, conv5的输出定义为{$C_2, C_{3}. C_{4}, C_{5}$} ,这些都是每个stage中最后一个残差块的输出,这些输出分别是原图的{$\frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{32}$}倍,所以这些特征图的尺寸之间就是2倍的关系。
top-down
Top-down的过程就是将高层得到的feature map进行上采样然后往下传递,这样做是因为,高层的特征包含丰富的语义信息,经过top-down的传播就能使得这些语义信息传播到低层特征上,使得低层特征也包含丰富的语义信息。本文中,采样方法是最近邻上采样,使得特征图扩大2倍。上采样的目的就是放大图片,在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的像素,在本文中使用的是最近邻上采样(插值)。这是最简单的一种插值方法,不需要计算,在待求像素的四个邻近像素中,将距离待求像素最近的邻近像素值赋给待求像素。
最邻近法计算量较小,但可能会造成插值生成的图像灰度上的不连续,在灰度变化的地方可能出现明显的锯齿状。
Lateral connection
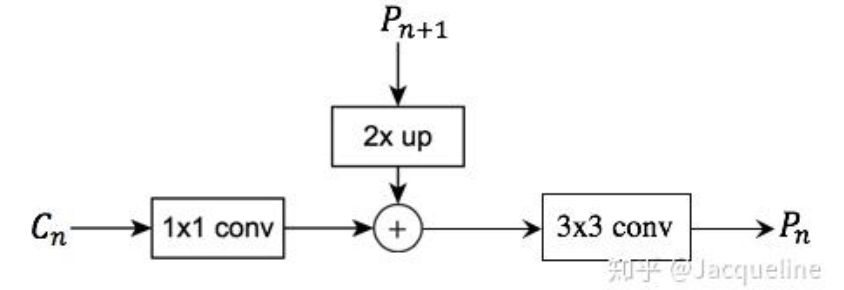
- 对于每个stage输出的feature map $C_{n}$,都先进行一个1*1的卷积降低维度。
- 然后再将得到的特征和上一层采样得到特征图$P_{n+1}$进行融合,就是直接相加,element-wise addition。因为每个stage输出的特征图之间是2倍的关系,所以上一层上采样得到的特征图的大小和本层的大小一样,就可以直接将对应元素相加 。
- 相加完之后需要进行一个3x3的卷积才能得到本层的特征输出$P_{n}$。使用这个3x3卷积的目的是为了消除上采样产生的混叠效应(aliasing effect),混叠效应应该就是指上边提到的‘插值生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状’。在本文中,因为金字塔所有层的输出特征都共享classifiers/ regressors,所以输出的维度都被统一为256,即这些3x3的卷积的channel都为256。
FPN&RPN
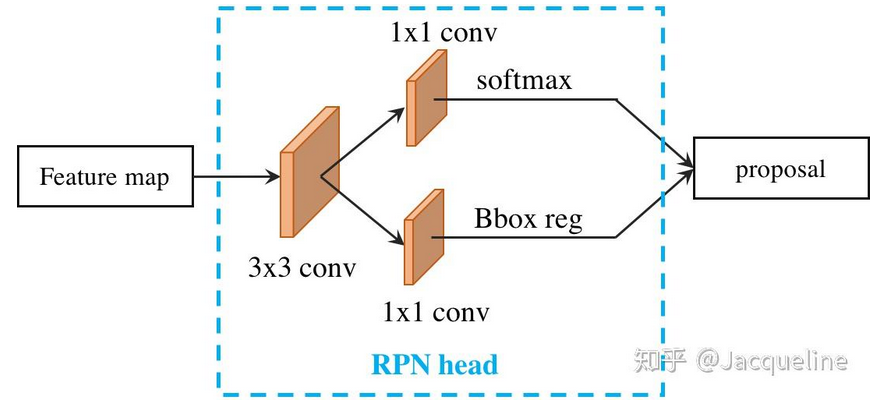
下图所示为Faster R-CNN中的RPN的网络结构,接收单尺度的特征输入,然后经过3x3的卷积,并在feature map上的每个点处生成9个anchor(3个尺寸,每种尺寸对应3个宽高比),之后再在两个分支并行的进行1x1卷积,分别用于对anchors进行分类和回归。这是单尺度的特征输入的RPN。
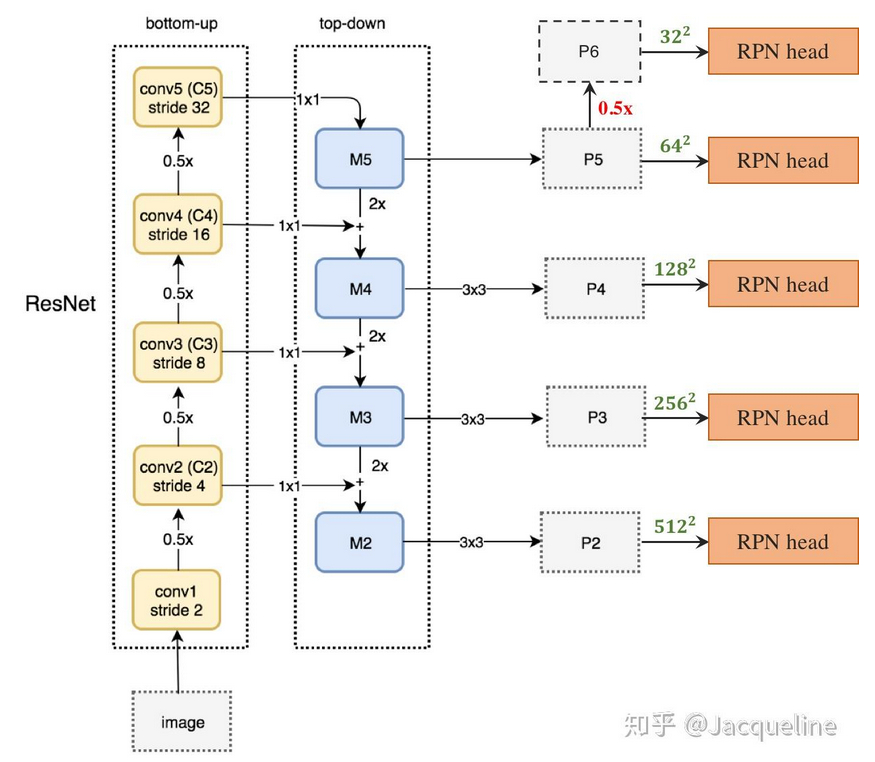
Formally, we define the anchors to have areas of {$32^2, 64^2, 128^2, 256^2, 512^2$} pixels on {$P_2, P_3, P_4, P_5, P_6$}
在生成anchor的时候,因为输入是多尺度特征,就不需要再对每层都使用3种不同尺度的anchor了,所以只为每层设定一种尺寸的anchor,图中绿色的数字就代表每层anchor的size,但是每种尺寸还是会对应3种宽高比。所以总共会有15种anchors。此外,anchor的ground truth label和Faster R-CNN中的定义相同,即如果某个anchor和ground-truth box有最大的IoU,或者IoU大于0.7,那这个anchor就是正样本,如果IoU小于0.3,那就是负样本。此外,需要注意的是每层的RPN head都参数共享的。
Feature Pyramid Networks for Object Detection


